Computer-Augmented Techniques for Musical Articulatory Synthesis
This is a project proposal I made as part of an application for a PhD program. I've slightly adapted it to work better as a wiki page. Ultimately, it got rejected, but I was very close to getting the position.
Included in this page is also a transcribed version of the 5-minute presentation I made to pitch this proposal during the interview. This can be found in the Prelude.
This work is placed under the CC BY-SA 4.0 creative commons license.
Prelude
The overal objective of this project aims to explore and discover new ways to control artificial voice in a musical context.
To better understand the interest and perspectives of this project, consider this video of Sir Ian McKellen performing the opening lines of "The Merchant of Venice", with direction from Sir John Barton.
What if computers could perform melodies like this?
In a performance, it often happens that the way something
is said (known as prosody) has equal value to the words
themselves. In other words, it's not what, but how you say something that matters.
As a computer music composer, I am fascinated by this idea,
and have a strong interest in exploring this concept in
my work.
As it turns out, vocal-like instruments and sounds lend
themselves really well towards musical prosody. For this
reason, I've been very interested in vocal synthesis
techniques, and in particular, articulatory synthesis.
Articulatory synthesis is a unique approach for producing artificial voice that works by simulating the human vocal tract. Through shaping this virtual vocal tract in different configurations one is able to produce different phonemes, the building blocks of speech, out the other side.
It is a truly malleable method of speech synthesis, with much potential for musical expression unrelated to speech. To demonstrate this, I have created a little Android App that allows one to "sculpt" a simple vocal tract in an articulatory synthesizer. In doing so, it dramatically changes the timbre of the voice.
Abstract
Articulatory Synthesis is a branch of speech synthesis that
uses physically based models of the human
vocal tract for sound production. While these methods
can yield high quality results, the large number
of parametric inputs makes them difficult to control.
This research aims to develop novel techniques that utilize
AI to help musically manipulate and perform these models.
Musical interfaces will be constructed with AI-assistance to
explore sound spaces.
Design principles involving
so-called anthropomorphic sensitivity to the
disembodied artificial
human voice will be formally investigated.
Objectives and Research Questions
The Main Objective
The proposed research efforts outlined below aim to enable individuals to puppeteer computers and get them to ``sing''. It is the hope that the results of these investigations will uncover new musical interactions using the computer medium.
The choice of imitating the human was deliberate. Arguably our oldest companion to music, the voice taps into profound parts of the human experience, and can be used to establish a strong link between the music that brought us here and the music that awaits us.
Research Questions
This research proposal aims to directly address the following questions:
What are the ways that AI can be used to help musically manipulate and perform physically based vocal tract models?
Broadly speaking, it is expected that AI techniques will be used in the problem domain of dimensionality reduction. At the lowest level, this means using AI to find vocal tract parameter spaces that approximate an ideal vowel shape. Higher abstraction layers will be built on top of this work that explore AI in the context of gesture and ensemble.
What are the ideal interfaces for articulating disembodied artificial voices?
Because the sounds produced relate so closely to the human voice, interfaces require a degree of anthropomorphic sensitivity, or an awareness of how humans generally respond to the uncanny nature of disembodied artificial human voices.
How can these new techniques be utilized to push the sonic boundaries of these models?
This research question grounds itself in the aspirations of computer music composers. These articulatory synthesis models, while purpose-built for synthesizing speech, need not be limited to producing spectra associated with the human voice. Hopefully, the control techniques developed will serendipitously uncover new musically compelling timbres and inspire new interfaces to control them. New algorithms lead to new controllers lead to new algorithms.
State of the Art and Background
Research in Articulatory Synthesis for Speech has been relatively stagnant in the last decades, with Deep Learning being more favored. Musical applications for Articulatory Synthesis such as singing are even rarer to find. We are well overdue for a renaissance.
The Voder
In the late 30s, Bell Labs created the Voder , an interface for controlling an electronic voice. Despite being synthesized using rudimentary electrical components, its interface gave it a surprising range of speech prosody . The Voder was notoriously difficult to control, and very few people were capable of effectively performing with it. Often this is the trade-off with control of artificial voice; it is difficult to have interfaces for artificial voice control with high ceilings and low floors .
The 60s: Bell Labs and the Golden Age of Vocal Synthesis
Physically-based computer models for the vocal tract have
been around since the 60s, and singing computers have
existed for almost as long. 1962, John L. Kelly and Carol C.
Lochbaum published one of the first software implementations
of a physical model of the vocal tract. The previous year, it was
used to produce the singing voice in "Daisy Bell"
by Max Matthews, the first time a computer was taught
to sing, and perhaps one of the earliest significant works of
computer music. This work went on to influence the
creation of HAL in 2001: a Space Odyssey, and
set up expectations for the disembodied computer voice.
The Rise of the Personal Computer
In the 70s and 80s, computer hardware began to change with the rise of the personal computer. Faster but lower-quality sounding speech techniques such as LPC, concatenative synthesis, and formant synthesis were able to better leverage the new hardware.
In 1991, Perry Cook published a seminal work on articulatory singing synthesis. In addition to creating novel ways for analyzing and discovering vocal tract parameters, Cook also built an interactive GUI for realtime singing control of the DSP model. This was perhaps the earliest time such models could be performed in realtime, thanks to hardware improvements.
Vocaloid and Virtual Pop Stars
In the early 2000s, a commercial singing synthesizer known as Vocaloid was born. Under the hood, Vocaloid implements a proprietary form of concatenative synthesis. Voice sounds for Vocaloid are created by meticulously sampling the performances of live singers. Still in development today, Vocaloid has a rich community and is considered "cutting-edge" for singing synthesis in the industry.
One of the interesting things about Vocaloid is how they address the uncanny valley issues that come up when doing vocal synthesis. Each voice preset, or "performer", is paired with a cartoon anime performer with a personality and backstory. Making them cartoons steers them away from the uncanny valley. Unlike most efforts in speech synthesis, fidelity and even intelligibility are less important. As a result, Vocaloid has a distinct signature sound that is both artificial yet familiar.
Musical Singing interfaces on the Interactive Web
Developments of the web browser in the last ten years have yielded very interesting musical interfaces for synthesized voice.
In the mid 2010s, Neil Thapen developed the web app Pink Trombone , touted as a low-level speech synthesizer. The interface is an anatomic split view of a vocal tract that can be manipulated in realtime using the mouse. The underlying model is a variation of the Kelly-Lochbaum physical model, utilizing an analytical LF glottal model . Pink Trombone served as the basis of Voc \cite{Voc}, a port I made of the DSP layer to ANSI C using a literate programming style.
Much of Neil Thapen's work in Pink Trombone can be traced back to Jack Mullen's DSP dissertation on using 2d waveguides vocal tract control.
In around 2018, Adult Swim released Choir, a web audio powered virtual singing quartet with interactive visuals by David Li with sound design by Chris Heinrichs. Chords are allegedly found using machine learning. In 2020, Li and Google Research teamed up to release Blob Opera, essentially a second iteration of Choir. Blob Opera and Choir both sound physically based, but I can't confirm this, as the source code is not public.
Postlude: Deep Learning
Recently, there have been early attempts at using deep learning to synthesize singing . While it is true the output results are impressive, these are still speech synthesis studies in musicians' clothes, as they tend to focus on fidelity rather than expression.
Research Methodology
The research involved in investigating novel computer-augmented techniques for musical articulatory synthesis can be broken down into the following: developing mental models and frameworks, demo-driven development, and validation studies.
Mental Models and Frameworks
Articulating a
disembodied artificial voice requires developing
mental models and frameworks that break up the problem into
smaller components. The first proposed structure is what I
will refer to as
the Instrument Pipeline. The Instrument Pipeline maps
the high-level components
for a hypothetical musical performance interface. It is
divided into four layers: interface, mapping, model, and
sound.

The Interface Layer concerns itself with the
human-computer interactions. Interfaces include peripherals
like keyboard and mouse, gamepads, MIDI controllers, or
other homegrown sensors built using arduino or similar
maker components.
Previous projects such as the Contrenot, Eyejam, or Ethersurface, as well as my work with the Soli and Leap Motion, provide some insight into how I approach physical interfaces in computer music. Built from simple electronics or off-the-shelf devices, control schemes from these physical interfaces always get developed building off of their natural affordances.
The Sound Layer is responsible for
emitting
sound. For the purpose of this research, the scope of sound
transmission sources will be limited to conventional
speakers and headphones.
The Model Layer is the DSP algorithm that contains the
physical model of the human vocal tract. It is the layer
that synthesizes PCM data which is then converted to
analogue sound via the DAC.
The Mapping Layer sits between the Interface and
Model, and is in charge of converting musical vectors of
expression produced by the interface into input parameters
for the model. This mapping layer is anticipated to be the
core
area of research, and where most of the applications of
AI-based techniques will be utilized. To fully address the
micro and macro concerns for musically meaningful
instruments, mapping must be elaborated on further with
another framework, in what
will be called The Hierarchy of Control. It considers
three scales of control: timbre, gesture, and ensemble:
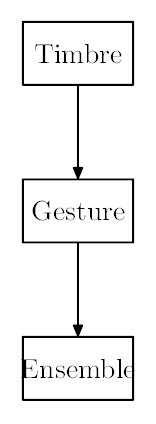
The Timbre scale is the lowest level of control,
and concerns itself with manipulating the parameter space
of vocal tract models in question. Research will go into
using AI techniques to find meaningful vocal tract
shapes.
The Gesture scale of control abstracts everything into
gestures, continuous trajectories.
Gestures are used to navigate the timbre space,
and it is here that the perceptual event of
a musical note is formed within a phrase. Within this
framework, gestures can be synthesized or analyzed from
continuous controller interface events.
AI intervention will be used to assist these processes.
At the Ensemble scale of control,
the paradigm shifts from manipulating one voice to many.
The role of the human performer becomes one similar to a
conductor, with a focus on macro structure rather
than individual sound events.
Voices take on more self-described behavior,
moving independently with an awareness of the other voices.
No era quite captures the beauty of
vocal counterpoint like those found in Renaissance Sacred
Choral Music two centuries prior to Fux's Gradus ad
Parnassum.
Inspiration for
control and rules will be found studying the works of
sacred choral works from renaissance composers such as
Palestrina, as well as
late-medieval works like those from the Ars Nova.
Demo-Drive Development
In my works I employ an iterative process
that I call Demo-Driven Development: the
creation of tightly scoped works designed to
investigate a particular idea.
This is typically in the form of some kind
compositional etude with
varying degrees of technicality,
or an interactive sound toy. An effective
demo will inspire conversations that bring momentum for
the next iteration. This particular kind of process is
important for grounding
research in things that are in the bounds of
"musically meaningful".
Consider my musical DSP library called Soundpipe. In my initial attempts at composing with Soundpipe, I found it too low level for creative thought. This problem created Sporth, a stack-based language built on top of Soundpipe that could tersely build modular patches. After using Sporth to compose music, it was adapted to work as a live-coding coding environment. This tightened the creative feedback loop. Performance became an issue, so the whole tool was rewritten to be faster. Because more could be done in realtime, the complexity of the patches grew, and new abstraction layers were desired. High level languages like Scheme were introduced with tight integration with the Monome Arc and Grid, which is now the current iteration.
Validation Studies
Validation studies will attempt to quantify ideal characteristics for interfaces articulating disembodied artificial voice.
These studies attempt to measure three qualifiers that make up a musically meaningful interface: expressiveness, intuitiveness, and anthropomorphic sensitivity.
The structure of these studies will consist of surveys and experiments utilizing generated stimuli that are both interactive and non-interactive. Participants will be split into those with and without formal musical training.
Ethical Considerations
Any research projects involved in synthesizing human-like sounds or visuals should proceed with great caution. While this project is indeed related to realistic human speech synthesis, the ethical considerations as it relates to issues like deepfakes is anticipated to be minimal. Rather than set out to make a musical speech engine, this research intends to approach the voice as a musical instrument and a template for exploring new complex timbres and sound structures.
Indicative Timeline
Deliverables
The deliverables of this research project come in three forms: the Dissertation, the Implementation, and the Demonstration. These will be developed over the allocated three year period. While much may change over that time, it is anticipated that these will remain consistent pillars.
The Implementation will be software based on the research discussed in the Dissertation. This will most likely be written as a literate program, a programming paradigm invented by Donald Knuth, which has seen success in many large-scale projects.
The Demonstrations, built on top of the Implementation, will be crafted to convey a core idea found in the novel research. It is anticipated that at least two interfaces will be built. One interface will have a musical instrument form factor exploring timbre and gesture scales of control. The other interface will explore ensemble and gesture scales.
Timeline over 3-year period
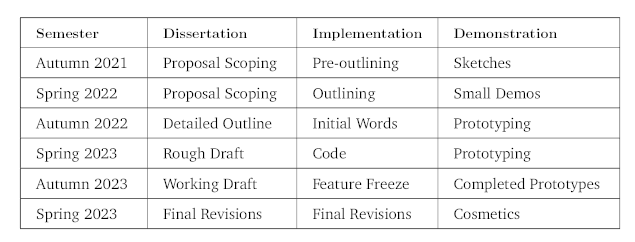
It is sensible to align the timeline events with the academic calendar of the University, which breaks up the 3-year period into 6 semesters between Autumn 2021 and Spring 2024.
The first and last semesters will be for general orientation and final revisions, respectively.
The first 3 semesters will have a heavy focus on the Demonstration and Implementation. After that, the focus will shift towards Dissertation and Implementation.
The initial research period of the first year is an important time for scoping and planning. A large emphasis will be placed on demo-driven development. This will help build up an intuition of the domain that will propel into the work done in the second year.
The second year aims to be a busy one. Any kind of fabrication plans or experiment design needs to begin happening by early Autumn 2022 at the latest, as these have a considerable number of moving parts. Spring 2023 will be a crunch to complete as much as possible in order to gracefully meet the deadline in the following year.
The final year is wrap-up. By winter break, all three deliverables should feel comfortably close to completion. The final Demonstrations should be done at this point. By Spring 2024, work should wind down to final revisions and tweaks.
home | index